
Extract Structured Data from Any Document with LLMs
Turn documents like PDFs, Word files, and images into structured, validated JSON using AI. Open-source and easy to integrate into your applications.
What is Data Wizard?
Data Wizard is an open-source tool that uses Large Language Models to pull structured data from various documents – regardless of their size or format.
Simply define your desired output using JSON Schema, pick an Extraction Strategy, choose your LLM (like OpenAI, Anthropic, or local models), and let Data Wizard extract and validate the data.
Ideal for automating data entry or adding smart import features to your apps. Integrate via iFrame or use programmatically with the REST/GraphQL API.
Get started with Docker
Using Data Wizard is as simple as running a single Docker command. In just a few minutes, you can have a fully functional instance of Data Wizard up and running, ready to process your documents – self-hosted and on your own infrastructure.
Data Wizard stores uploaded files on your local disk and uses SQLite to manage your data.
docker run \ --name data-wizard \ -p 9090:80 \ -p 4430:443 \ -p 4430:443/udp \ -v data_wizard_storage:/app/storage \ -v data_wizard_sqlite_data:/app/database \ -v data_wizard_caddy_data:/data \ -v data_wizard_caddy_config:/config \ -e APP_KEY=[REPLACE_WITH_APP_KEY] \ mateffy/data-wizard:latest
version: '3.8' services: data-wizard: name: data-wizard image: mateffy/data-wizard:latest ports: - "9090:80" - "4430:443" - "4430:443/udp" volumes: - data_wizard_storage:/app/storage - data_wizard_sqlite_data:/app/database - data_wizard_caddy_data:/data - data_wizard_caddy_config:/config environment: - APP_KEY=[REPLACE_WITH_APP_KEY] volumes: data_wizard_storage: data_wizard_sqlite_data: data_wizard_caddy_data: data_wizard_caddy_config:
Key Features
Flexible Extraction Engine
Define your exact data needs using standard JSON Schema. Data Wizard adapts its extraction process based on your schema, chosen LLM (like OpenAI, Anthropic, Mistral, or local models via Ollama/LMStudio), and selected processing strategy to fit the complexity of any document.
Seamless Integration
Easily incorporate Data Wizard into your existing workflows. Embed the user-friendly upload component via an iFrame, interact programmatically using comprehensive RESTful or GraphQL APIs, or set up webhooks to receive real-time notifications with the extracted JSON data upon completion.
Robust Document Handling
Process a wide array of file types including PDFs (native and scanned), Word documents (DOCX), Excel spreadsheets (XLSX), images (PNG, JPG), and more. Built-in OCR automatically handles scanned documents, while image extraction and page screenshot generation provide crucial visual context to the LLM for improved accuracy.
Reference Embedded Images
Go beyond text extraction. Data Wizard can identify, extract, and associate images embedded within your documents (like product photos in a PDF catalog or diagrams in a report) with corresponding data points in the final JSON output, providing richer, more complete structured information.
Open Source & Extensible
Built with transparency and flexibility in mind. Deploy easily using Docker for self-hosting and complete data control. The MIT license allows permissive use, and the modular architecture enables developers to create and integrate custom extraction strategies or pre/post-processing steps for highly specialized workflows.
Validation & Reliability
Ensure data quality and consistency. After the LLM extracts information, Data Wizard rigorously validates the output against the provided JSON Schema. Only data that perfectly matches the defined structure, types, and constraints is returned, guaranteeing clean, reliable, and immediately usable JSON.
How it works
Configure Extractor
Define the data structure you need with JSON Schema. Select an LLM and an extraction strategy.
Upload Documents
Upload your files via UI, iFrame, or REST API. Supports PDFs, Word/Excel documents, images, and more.
Get Structured Data
AI extracts data & validates it against the schema. Receive clean JSON via UI, webhook, or API.
Extraction Strategies For Any Document
Choose the best strategy for your document type and complexity. Strategies control how documents are processed and sent to the LLM.
Simple
Sends the entire document (or as much as fits) to the LLM in one go. Best for small documents.
Sequential
Processes document chunks one by one, feeding results from the previous chunk into the next prompt. Maintains context.
Parallel
Processes document chunks independently and simultaneously. Good for documents with unrelated data points across pages.
Auto-Merging
Extends Sequential or Parallel. Concatenates results from chunks and runs a final LLM call to deduplicate. Helps prevent lost items.
Double-Pass
First pass uses Parallel, second pass uses Sequential to review and refine. Combines speed and accuracy. Supports auto-merging.
Custom Strategy
Build your own strategy in PHP by implementing an interface. Add custom logic, validation, or API calls.
Get started with Docker
Using Data Wizard is as simple as running a single Docker command. In just a few minutes, you can have a fully functional instance of Data Wizard up and running, ready to process your documents – self-hosted and on your own infrastructure.
Data Wizard stores uploaded files on your local disk and uses SQLite to manage your data.
docker run \ --name data-wizard \ -p 9090:80 \ -p 4430:443 \ -p 4430:443/udp \ -v data_wizard_storage:/app/storage \ -v data_wizard_sqlite_data:/app/database \ -v data_wizard_caddy_data:/data \ -v data_wizard_caddy_config:/config \ -e APP_KEY=[REPLACE_WITH_APP_KEY] \ mateffy/data-wizard:latest
version: '3.8' services: data-wizard: name: data-wizard image: mateffy/data-wizard:latest ports: - "9090:80" - "4430:443" - "4430:443/udp" volumes: - data_wizard_storage:/app/storage - data_wizard_sqlite_data:/app/database - data_wizard_caddy_data:/data - data_wizard_caddy_config:/config environment: - APP_KEY=[REPLACE_WITH_APP_KEY] volumes: data_wizard_storage: data_wizard_sqlite_data: data_wizard_caddy_data: data_wizard_caddy_config:
Under the Hood: The Process
1. Pre-processing
File contents are extracted and pre-processed. Text and images are separated, document page screenshots are taken.
2. Strategy & Schema
The strategy determines how to chunk your document and merge the data. The schema defines the output structure.
3. LLM Interaction
Document chunks are sent to the LLM until the full document is processed. The LLM generates JSON output.
4. Validation & Output
LLM output is validated against the schema. The LLM fixes its own mistakes. The final JSON is returned to the user.
See Data Wizard in Action
Get a glimpse of the intuitive interface and powerful features that make data extraction effortless.
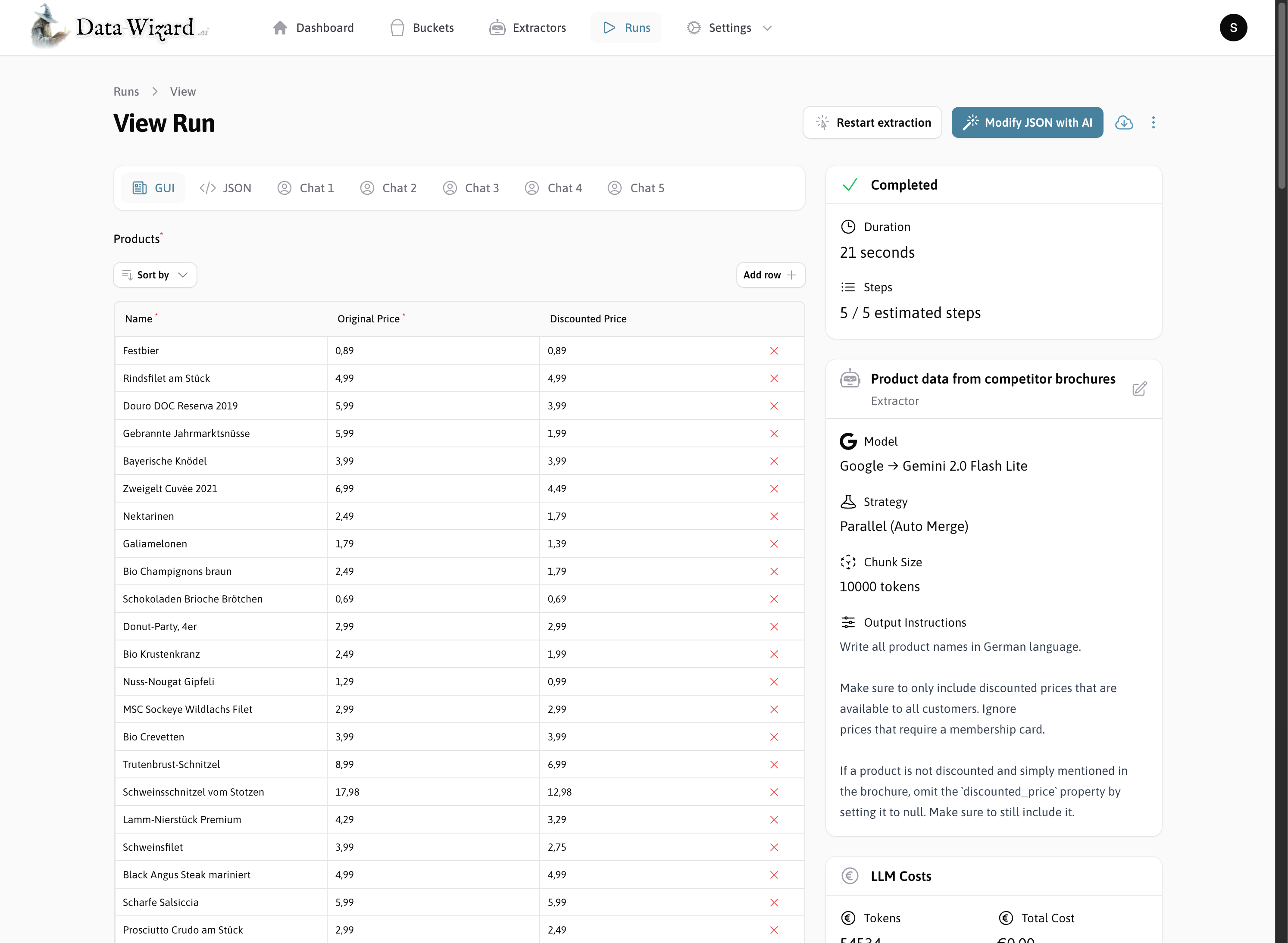
Standalone UI for running and evaluating extractors
The standalone UI allows you to run extraction tasks manually, which also helps evaluating and debugging your extractor.
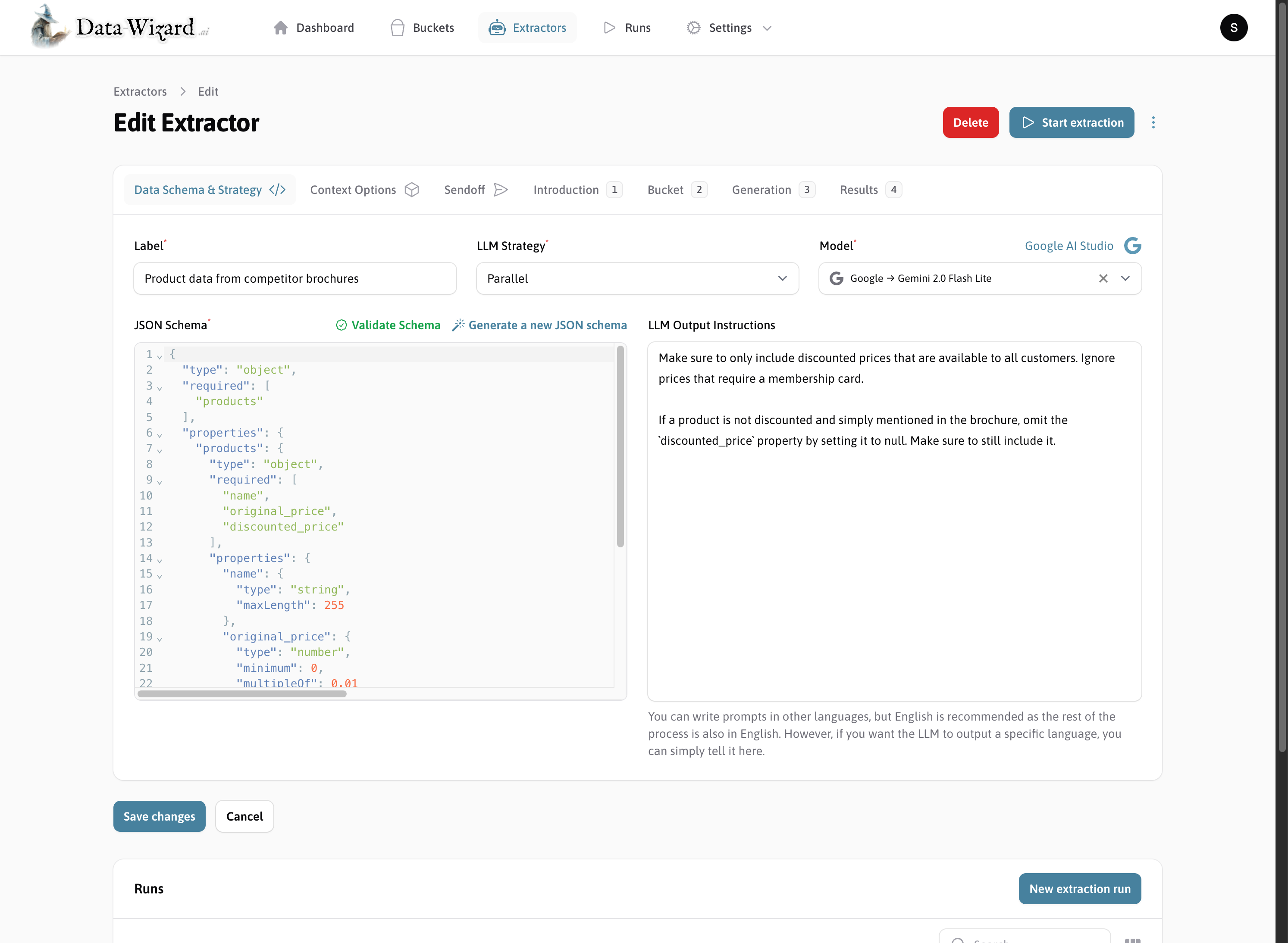
Reusable Extractors for different documents
Create reusable extractors for different documents. The built-in extractor editor allows you to define the JSON Schema, configure extra instructions & the context window, as well as the extraction strategy.
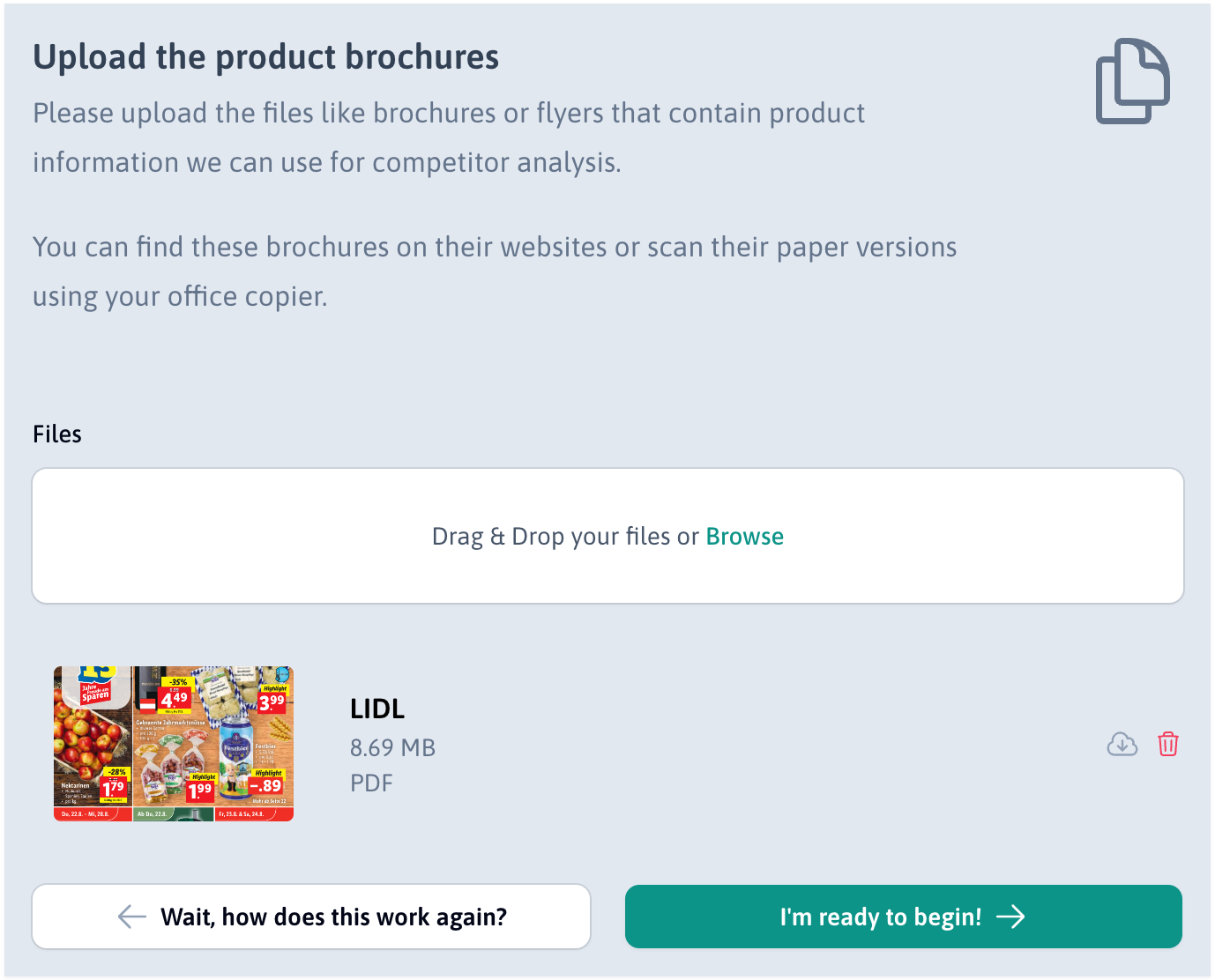
Uploaded files are processed in the background
Users can upload files via the UI. The files are pre-processed in the background, with the text and any embedded images being extracted from the PDF or Word file.
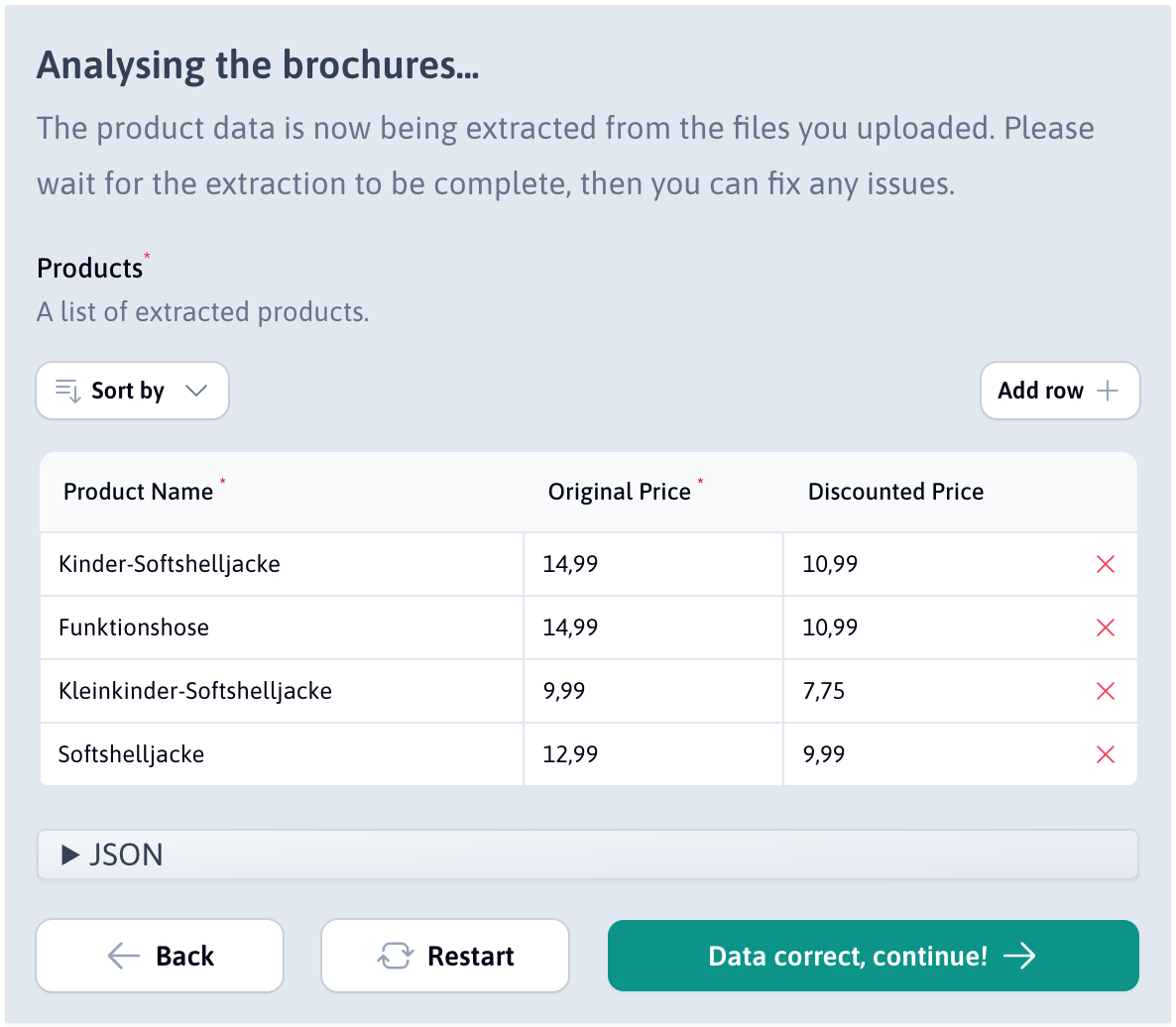
Generated UI based on JSON Schema
Easily embed Data Wizard in your app. Users can upload documents, edit JSON, and view results in a user-friendly interface.
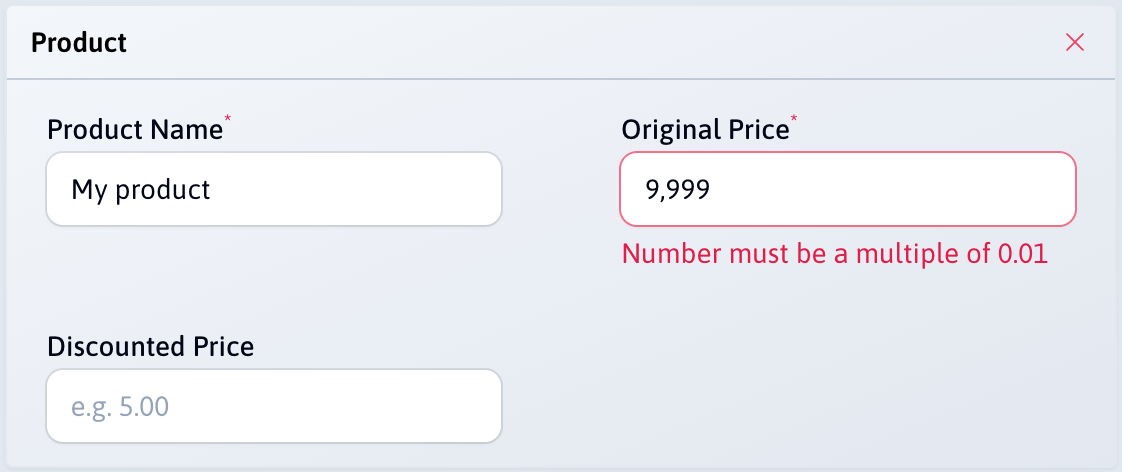
Data is validated against the JSON Schema
The JSON output is validated against the JSON Schema, including rules like minLength or multipleOf.
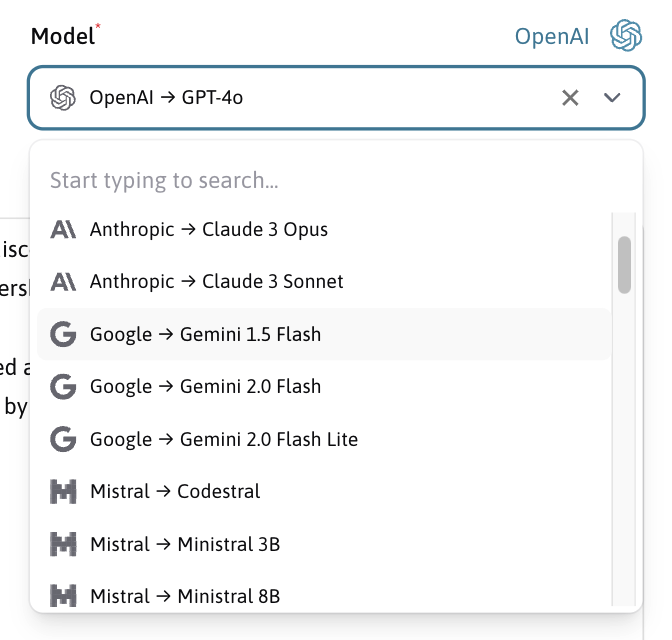
Select from a variety of LLMs
Data Wizard is not limited to a single LLM provider. You can choose from a variety of LLMs, including GPT-4, Claude and Gemini.
Get started with Docker
Using Data Wizard is as simple as running a single Docker command. In just a few minutes, you can have a fully functional instance of Data Wizard up and running, ready to process your documents – self-hosted and on your own infrastructure.
Data Wizard stores uploaded files on your local disk and uses SQLite to manage your data.
docker run \ --name data-wizard \ -p 9090:80 \ -p 4430:443 \ -p 4430:443/udp \ -v data_wizard_storage:/app/storage \ -v data_wizard_sqlite_data:/app/database \ -v data_wizard_caddy_data:/data \ -v data_wizard_caddy_config:/config \ -e APP_KEY=[REPLACE_WITH_APP_KEY] \ mateffy/data-wizard:latest
version: '3.8' services: data-wizard: name: data-wizard image: mateffy/data-wizard:latest ports: - "9090:80" - "4430:443" - "4430:443/udp" volumes: - data_wizard_storage:/app/storage - data_wizard_sqlite_data:/app/database - data_wizard_caddy_data:/data - data_wizard_caddy_config:/config environment: - APP_KEY=[REPLACE_WITH_APP_KEY] volumes: data_wizard_storage: data_wizard_sqlite_data: data_wizard_caddy_data: data_wizard_caddy_config:
Example Use Cases
Automate Data Entry
Extract from invoices, receipts, forms into ERP/accounting systems.
SaaS Smart Import
Let users upload documents to populate data in your CRM or SaaS app.
Document Conversion
Turn document batches (PDFs, scans) into structured JSON/CSV.
Core Extraction Engine
Power your document processing platform with Data Wizard's API.
Market Research
Gather product/pricing data from competitor brochures or websites.
Compliance Checks
Extract specific clauses or data points from contracts or reports.